News
Subscribe to the Australian BioCommons monthly newsletter or read previous editions
Deep learning meets genome annotation: rapid gene prediction tool now available
The deep learning-based genome annotation tool, Tiberius, is now available in Galaxy Australia. After being wrapped and extensively tested, it is freely available for everyone’s use in the Genome Lab.
The deep learning-based genome annotation tool, Tiberius, is now available in Galaxy Australia. After being wrapped and extensively tested, it is freely available for everyone’s use in the Genome Lab.
Tiberius offers gene structure prediction from genomic sequences alone (ab initio). With accuracy that matches tools using extrinsic data, it provides end-to-end prediction of protein-coding genes. Tiberius can be installed and run by individuals, and also parallelised on HPC systems. But now that the wrapper is available in the Galaxy toolshed, it can easily be used by Australian researchers in the Galaxy Australia platform (or installed on any other international Galaxy instance). Tiberius has been trained on organisms in Bacillariophyta, Chlorophyta, Fungi, Insecta, Mammalia, Mesangiospermae, and Vertebrata, and all of those models are available on Galaxy.

Image: Getty Images via Canva
During an internship with the Australian Tree of Life Bioinformatics team, University of Queensland PhD candidate, Jane Tung, did much of the initial work to get Tiberius up and running. She benchmarked the performance of three traditional and two machine learning-based eukaryotic genome annotation pipelines using datasets spanning fungi, plants, insects, fish, lizards, amphibians, birds and mammals. Tiberius completed the annotation in a fraction of the time and used fewer resources compared to the traditional pipelines, without a negative effect on quality metrics. Jane will be discussing these findings further in November via the webinar ‘Benchmarking the latest annotation pipelines on Australian reference genomes’.
The performance of Tiberius without RNAseq data made this tool the perfect candidate for rapid gene prediction on assemblies produced by the Genome Engine in the Australian BioCommon’s Australian Tree of Life (AToL) project. It has become an essential part of the Genome Engine that will enable rapid, automated assembly, annotation and publication of genomes.
While Tiberius was prioritised for inclusion as part of the AToL project, individual researchers can also request the installation of new tools or datasets in Galaxy Australia. For researchers wanting to contribute to the international open source Galaxy community directly, there are supportive guidance videos for DIY tool wrapping. Proactive community members recently took up the challenge, and collaborated with BioCommons to make the first dedicated glycomics tool and workflow available on Galaxy.
Try out Tiberius in Galaxy Australia’s Genome Lab
Register for the webinar Benchmarking the latest annotation pipelines on Australian reference genomes
Dr Sarah Beecroft recognised with national award for research enablement
Australian BioCommons is proud to announce that Dr Sarah Beecroft has been awarded the 2026 Early Career eResearch Excellence Prize by AeRO. The prize recognises Sarah’s excellence in research enablement, technical innovation, collaboration, and community leadership.
Australian BioCommons is proud to announce that Dr Sarah Beecroft has been awarded the 2026 Early Career eResearch Excellence Prize by AeRO. The prize recognises Sarah’s excellence in research enablement, technical innovation, collaboration, and community leadership.
After many years of productive collaboration with Sarah, BioCommons now invests directly into Sarah’s role as Lifescience Applications Specialist at the Pawsey Supercomputing Research Centre. BioCommons co-funds this role with Pawsey in recognition that her work to support bioinformatics users through workflow development and optimisation, training, and advocacy is so integral to the success of life science research in Australia.

Sarah’s participation has been key to the delivery of many significant research outcomes, including the recent extraordinary addition of 17 million protein predictions to an international open access database by an Australian researcher, made possible by Sarah’s porting of workflows to enable usage of Setonix's AMD GPUs at Pawsey.
It is wonderful to see that Sarah’s outstanding contributions to the eResearch community have been recognised with one of the AeRO awards. Congratulations Sarah, and keep up the good work!
Sarah regularly shares her expertise via BioCommons training events. You can catch up on the recording of her recent Using Containers in Nextflow session.
Powering discovery: diverse outputs from ABLeS-enabled research
The Australian BioCommons Leadership Share (ABLeS) has been providing access to infrastructure and computational resources for over 5 years, enhancing the capacity of life scientists to readily harness national infrastructure to accelerate their discoveries. The publications generated by 73 projects involving 471 ABLeS users provide a fascinating insight into the diversity of research requiring large-scale computational power for bioinformatics.
The Australian BioCommons Leadership Share (ABLeS) has been providing access to infrastructure and computational resources for over 5 years, enhancing the capacity of life scientists to readily harness national infrastructure to accelerate their discoveries. Working with Australia’s Tier 1 high-performance computing facilities, Pawsey and NCI, this Australian BioCommons program provides computational resources, specialist expertise, and a shared repository of tools and software, tailored to support life science research communities.
The publications generated by 73 projects involving 471 ABLeS users provide a fascinating insight into the diversity of research requiring large-scale computational power for bioinformatics. Project leads have shared outputs from the first half of the year, offering a snapshot of how ABLeS is supporting research across a diverse range of areas.
As part of the Australian Amphibian and Reptile Genomics initiative (AusARG), Dr Ian Brennan, ANU, leveraged Pawsey compute to document the phylogenomics of native animals:
Prof Benjamin Schwessinger (ANU) from the Plant Pathogen Omics Initiative has used NCI to create outputs that report on stripe rust, the economically significant pathogen of barley and wheat:
Over the years, access to the right national facilities has underpinned the ability of research groups to analyse and process their data. Dr Patricia Agudelo-Romero, and her team The Kids Research Institute, have been utilising their Pawsey resources to great effect, with publications across domains:
Exploring the complexity of the human respiratory virome through an in silico analysis of shotgun metagenomic data retrieved from public repositoriesConservation of gene expression patterns between the amniotic and nasal epithelium at birth
Programming of the respiratory epithelium in utero — insight from the amniotic epithelial methylome
Dr Agudelo-Romero remarked:
“Through ABLeS computing resources, the research I lead at The Kids Research Institute Australia has enabled multi-omics analyses in paediatric respiratory research, including epigenomics, transcriptomics, and metagenomics. This support has facilitated studies ranging from characterising the human respiratory virome to understanding early-life epigenetic programming of the airway, as well as building sustainable bioinformatics capacity through Nextflow and nf-core training.”
Australian BioCommons encourages ABLeS project teams to share publications, software, datasets and other outcomes arising from their allocations so they can be showcased across the community. These examples represent only a small sample of the diverse research communities currently supported through ABLeS. As the BioCommons’ Product Manager, Bioinformatics Platforms, Dr Ziad Al Bkhetan has been thrilled to see the ABLeS service grow:
The publications that are rolling in clearly demonstrate the uplift that happens when ABLeS connects researchers directly to the computational resources they need. Now in its fifth year, ABLeS continues to expand, enabling more projects to take full advantage of the excellent research infrastructure available to Australian researchers.
Learn how ABLeS can support your research
ABLeS is co-funded by Bioplatforms Australia, National Computational Infrastructure and Pawsey Supercomputing Research Centre
Exchanging ideas with European research infrastructures at ELIXIR All Hands
Australian BioCommons join ELIXIR’s All Hands meeting in France this month, an international gathering to share insights and address the challenges of building and sustaining distributed life science data infrastructure.

L-R: Jo Wingender, Tiff Nelson, Melissa Burke, Jess Holliday, Flora Foltanyi, Andy Smith
Key members of the Australian BioCommons team travelled to the ELIXIR All Hands meeting in June to share our insights in building and sustaining distributed life science data infrastructure with European peers. Each year, three staff represent Australia’s activities to more than 500 professionals from over 25 countries. Participants share their successes and seek ways to collaboratively address ongoing challenges facing life science research infrastructures.
ELIXIR, as Europe’s life science research infrastructure, has a mission that is closely aligned with that of Australian BioCommons, and we have maintained a collaboration strategy since 2020. With ongoing face to face interactions a key component of the strategy, Australian BioCommons was well represented at the 2026 All Hands meeting with Dr Melissa Burke, Dr Tiff Nelson, and Jess Holliday attending in Lyon, France.
Immersion in the international life science research infrastructure landscape offered insights across the board, from the technical to the policy level. The opportunity to connect with colleagues in person benefits our normal late-night online meetings across different time zones, making global collaboration possible, more fun and ultimately more successful.
Training Manager, Melissa, reflected, “Collaboration and ‘people infrastructure’ was a standout theme of the meeting. Keynote presentations, symposia and workshops showcased how the networks and collaborations established by ELIXIR are driving cross-border tech solutions like AI factories and federated healthcare data, and influencing European Open Science policy. Investing in people infrastructure by developing research infrastructure staff was noted as key to long term sustainability and strength.”
With the GUARDIANS program entrusted with building national-scale capabilities to support biomedical research using sensitive human omics data, Human Genome Informatics Program Manager, Jess, was keen to hear how international peers are tackling aligned challenges. The opportunities to exchange ideas with the experts gathered from many countries did not disappoint, and Jess returned with nuanced insights into complex national collaborations.
Community Engagement Lead, Tiff, led a workshop to collectively examine current practices and identify opportunities for improving engaging user communities for better services: Building and Operating Fit-for-purpose Services and Platforms through Collaborative User Engagement. It was a wonderful opportunity to highlight the importance of scientific community engagement and showcase the widely-respected process that BioCommons undertakes to build valuable services for life scientists. Tiff was excited to see new tools that have been developed for ELIXIR communities and looks forward to sharing what she’s learnt with Australian researchers.
Our role in building Australia’s research future
To celebrate some of NCRIS’s many successes, the Department of Education has produced a booklet which includes a case study that describes how Australian BioCommons supported the automation of data processing for better border biosecurity.

For more than 20 years, the National Collaborative Research Infrastructure Strategy (NCRIS) has been a cornerstone of Australia’s research success. NCRIS-supported facilities have played a key role in addressing national priorities.
Approximately $5.5 billion has been invested in large, long-term, highly collaborative and national scale projects led by universities, government agencies and private companies to support world-class research. This of course includes investment in people and operations, not just equipment.
NCRIS provides equipment, data, services and expertise to enable world-leading research, development and translation for the benefit of all Australians.
The infrastructure is open to anyone – academics, industry, government and the general public – and is co-funded by state and territory governments, industry, universities and research agencies to minimise costs.
The research infrastructure providers enabled by NCRIS includes Bioplatforms Australia which enhances Australian life science research by investing in state-of-the-art infrastructure and expertise in genomics, proteomics, metabolomics, synthetic biology - and bioinformatics, through Australian BioCommons.
Managed and overseen by the Australian Government, NCRIS has delivered a wide range of national benefits. To celebrate some of its many successes, the Department of Education produced a booklet which included a case study that describes how Australian BioCommons has supported a research group to automate their data analysis for better border biosecurity.
Read Celebrating 20 Years of the National Collaborative Research Infrastructure Strategy (NCRIS).
World-leading Australian science: 17M protein structures added to the AlphaFold Database to accelerate the fight against antimicrobial resistance
Australian researcher, George Bouras, has recently contributed an extraordinary 17 million protein predictions to the AlphaFold Protein Structure Database. This work was possible thanks to the availability of the ColabFold tool on Setonix AMD, the result of collaboration between BioCommons and the Pawsey Supercomputing Research Centre.
Australian researcher, George Bouras, has recently contributed an extraordinary 17 million protein predictions to an international open access database. The availability of the large-scale dataset in the AlphaFold Protein Structure Database will have a transformative impact on the international fight to combat antimicrobial resistance.
As the lead of the AllTheBacteria protein structure prediction project, the Adelaide University bioinformatician and current PhD student completed his world-leading work using resources made available through a BioCommons partnership with Pawsey Supercomputing Research Centre. George’s work became possible only when the right human and compute resources came together. Working closely with BioCommons, Pawsey’s Dr Sarah Beecroft containerised the ColabFold tool for use on Setonix's AMD GPUs. Once ColabFold was ported and stable, George could utilise the massive scale of Pawsey’s Setonix to create the 17 million structural predictions for bacterial proteins.
Source image: AlphaFold prediction of a banna virus spike protein VP4 (AF-0000000365762994-v1). Design credit: Karen Arnott/ EMBL-EBI.
George was honoured to contribute to the AlphaFold Database, one of several high-value datasets for microbial and viral proteins selected from specialist communities. This integration of essential, high-quality datasets from users reinforces the AlphaFold Database’s role as an inclusive, and community-driven resource. The database provides open access to over 200 million protein structure predictions, and the developers,Google DeepMind and EMBL’s European Bioinformatics Institute (EMBL-EBI), are wanting to expand their impact for specialist areas including pandemic preparedness, antimicrobial resistance, neglected tropical diseases and environmental sciences.
“I hope that access to these novel bacterial protein structures derived from high-quality genome assemblies will lead to better understanding of the function of all bacterial proteins.” – George Bouras, lead of the AllTheBacteria
The availability of the ColabFold container for use on Setonix’s AMD GPUs also allowed George to generate more than 3 million phage and viral structures, which are now used for protein structure-informed bacteriophage genome annotation hundreds of thousands of times each day by researchers around the world.
This example shows how close working relationships with both researchers and the Tier-1 HPC infrastructures enables BioCommons to precisely respond to community needs and accelerate Australian science at a scale. Making valuable tools accessible on national platforms is a focus of the BioCommons BioCLI project, and this work paves the way for the creation of a new national protein folding service further streamlining the use of Pawsey computing resources.
A publication about this work is currently under peer review, but in the meantime you can read the release from EBI.
GlyCombo: the first dedicated glycomics workflow on Galaxy
GlyCombo is now live on Galaxy Australia as the platform's first dedicated glycomics software tool. This high-throughput workflow, developed by Protea Glycosciences, offers researchers a streamlined, reproducible way to automate glycan identification from complex mass spectrometry data in just a few clicks.
In a win for the international glycomics community, the first dedicated glycomics and carbohydrate software tool is available on the global Galaxy platform thanks to a group of Australian researchers. GlyCombo, a high-throughput tool for glycan (sugar polymers present in protein samples) identification is now providing glycomics researchers with a streamlined, reproducible way to process their complex mass spectrometry (MS) data within Galaxy Australia. The workflow that performs a conversion of raw files, GlyCombo search, and visualisation of results glycan and polysaccharide compositions from mass spectrometry files has been shared through the publication on the GlyCombo Galaxy workflow on WorkflowHub.
The availability of this tool and workflow is the result of collaboration between the Galaxy Australia team and Protea Glycosciences, an innovative Australian glycosciences company based in Wollongong.

Dr Chris Ashwood and Dr Maia Kelly, Protea Glycosciences
By wrapping their open-source GlyCombo tool for Galaxy, Protea Glycosciences has made state-of-the-art analytical techniques accessible to researchers worldwide with just a few clicks.
How GlyCombo simplifies glycomics analysis
Rapid identification of glycans present in MS samples is a cornerstone of glycomics research and is integral to robust glycomics analysis pipelines, yet glycomics research is often limited by a lack of throughput and reproducible data analysis to enable subsequent structural elucidation. Protea Glycosciences was established in 2023 to address this gap, bringing a structure-oriented approach.
While traditional web-based tools utilise point-and-click interactions, GlyCombo enables researchers to rapidly process large-scale, complex MS datasets with greater efficiency and reproducibility. Through text-based commands, glycomics researchers can automate the assignment of monosaccharide combinations, handle multiple adduct searches, and anticipate off-by-one errors, while simultaneously maintaining detailed records of their analytical workflows.
The Galaxy GlyCombo workflow successfully monitored the glycomic consequences of biotransformation, detecting the drastic compositional shifts resulting from sialidase treatment directly within a fully reproducible, browser-based workflow.
Bringing the tool to Galaxy Australia
Protea Glycosciences have wrapped their open source tool for the platform, and the Galaxy Australia team have provided technical support to enable this easy access to the software. The integration of GlyCombo onto Galaxy Australia is a prime example of how national research infrastructure supports the Australian life sciences ecosystem, and how BioCommons and Galaxy Australia support industry-based Research and Development. Hundreds of researchers from Australian small-to-medium enterprises (SMEs) and startups use these subsidised services and the generous computational and working data storage quotas to accelerate their work.
“We built GlyCombo as an open-source tool to solve an analytical challenge, but software is only useful if people can run it. Galaxy makes complex workflows reproducible and accessible without local infrastructure or programming expertise. Partnering with Galaxy Australia was a direct path to putting rigorously tested glycomics workflows in front of researchers who need it and lowers the barrier to entry for the broader glycomics community.” - Dr Chris Ashwood, Director, Protea Glycosciences.
Learn more
Global collaboration advancing AI and biomedical data infrastructure
BioCommons brought together research data infrastructure experts from the USA, Finland, New Zealand and across Australia to strengthen the collaborative and technical capability required to build world-class human genomics and biomedical data infrastructure.
As part of a week-long international engagement program, BioCommons brought together research data infrastructure experts from the USA, Finland, New Zealand and across Australia. The Human Genome Informatics division at BioCommons hosted Prof Robert Grossman, University of Chicago, the founder and lead of the Gen3 platform, to strengthen the collaborative and technical capability required to build world-class human genomics and biomedical data infrastructure in Australia.
Participants engaged in a series of strategic discussions and technical demonstrations focused on solving the complex challenges of data commons development, federated data access, security and governance frameworks, and international interoperability initiatives.
Reflecting on the growing importance of research data infrastructure, Prof Matthew Watt, Associate Dean Research at the University of Melbourne’s Faculty of Medicine, Dentistry and Health Sciences, noted that ‘well-designed data ecosystems are no longer optional - they are foundational infrastructure for modern biomedical discovery.’

Prof Robert Grossman presenting during his seminar at the University of Melbourne
A particular highlight of the week was a seminar, ‘In Praise of Midscale Language Models and AI Commons and Their Applications to Biology, Medicine and Healthcare’, which sparked significant interest in how secure infrastructure can support the next generation of AI-driven biomedical research.
The discussions highlighted the value of strong international collaboration in advancing secure, scalable, and interoperable approaches to genomics and health data sharing, while also strengthening relationships across the global research infrastructure community. Participants noted the high quality of strategic conversations, which not only strengthened relationships but also reaffirmed Australia’s position as a leader in deploying these sophisticated systems.
How is Gen3 utilised in Australian human genomics research?
The Gen3 platform provides a robust framework to receive, manage, and describe massive datasets, allowing them to be shared securely with authorised users. It is the technology behind numerous US National Institutes of Health (NIH) projects that house data from hundreds of thousands of samples.
BioCommons has successfully led the implementation of Gen3 platforms for several landmark national projects, demonstrating our capability to adapt global best practices for the Australian research landscape. These include:
OMIX3: Led by the University of Melbourne, OMIX3 utilises mass spectrometry to enable the parallel collection of proteomics, metabolomics and lipidomics data, and is the first successful implementation of a Gen3 platform outside of the USA.
Australian Cardiovascular disease Data Commons (ACDC): Led by the Baker Heart and Diabetes Institute, ACDC provides a secure, Gen3-powered infrastructure to pool data from 400,000 individuals across 18 clinical cohorts.
Biological Psychiatry Data Commons (BPsych-DC): Led by the Consortium for Preclinical Psychiatric Research, providing a national digital infrastructure to harmonise multi-omics data across cellular, animal and human psychiatric models, bridging the gap between discovery and clinical impact
Prof Bernard Pope, GUARDIANS Program Lead and A/Director (Human Genome Informatics) at BioCommons, reflected on the highlights of the week:
‘Data commons are the backbone of collaborative genomic research. The ability to securely connect, govern, and analyse large-scale datasets is increasingly critical for translating research discoveries into meaningful health and clinical impact.’
‘The success of projects like OMIX3 and ACDC is built on years of shared expertise between our team and the architects of Gen3. By hosting international experts through the GUARDIANS program, we are ensuring that Australian researchers have access to the same secure, scalable technologies that power the world’s largest genomic projects.’
Take a closer look at the GUARDIANS Program: https://www.biocommons.org.au/guardians
Research communities can build their own digital labs with Australian innovation: Galaxy Labs Engine
The Galaxy Labs Engine is featured in a new paper detailing how researchers can build their own tailored digital labs. These bespoke interfaces provide curated tools and synchronised workflows that simplify complex, domain-specific bioinformatics for our community.
The Galaxy Labs Engine has been described in a new paper, including how it supports the easy creation of tailored research environments. Several domain-specific portals have now been generated on Galaxy Australia that guide researchers through curated and globally synchronised bioinformatics analysis resources
The Galaxy Labs Engine (GLE) allows research communities to build and synchronise their own Galaxy Labs, which guide users through curated tools, workflows, and training resources. These bespoke interfaces are especially helpful for researchers who are new to the analytical methods or technologies specific to the domain.

Galaxy Labs are an extension of the established feature of ‘Galaxy Flavours’, subdomains which offer curated content for specific research domains. However, these subdomains have been limited by having static deployments, being difficult to replicate across servers, and often provide inconsistent user interfaces. By separating the content from technical deployment, the engine allows research communities to build custom Labs that stay synchronised with global resources through GitHub.
Development of the GLE service was led by the Galaxy Australia team, originating from a project at the ‘Aussie Outpost’ of the ELIXIR BioHackathon Europe, hosted by Australian BioCommons in 2022.
The GLE has been used on the Galaxy Australia server to build the Microbiology and Single cell Labs, with the eDNA Lab currently being built, joining the Genome and Proteomics Labs as part of the expanding list of pre-configured Labs available. The engine is already being employed abroad by Galaxy France for their Ecology Lab, and to encourage global collaboration all Lab content is hosted in the Galaxy Project’s Codex GitHub repository.
Reflecting on how the team is always developing new ways to empower researchers, Galaxy Australia Product Owner Dr Gareth Price noted:
‘Our goal was to make constructing a Galaxy Lab an easy and accessible process for the whole community. Our team is already looking ahead as we finalise the deployment of an AI-assisted Lab builder, again reducing the technical barriers for researchers to start on their own Lab journey.’
You can read the paper in Gigascience
Explore the Galaxy Labs on the BioCommons website
Read Dr Gareth Price’s blog post on Galaxy News
Collaborating globally to develop a foundational structural biology training module
‘Foundations of protein structure’ is a new self-paced training module developed in collaboration with the Australian Structural Biology Computing (ASBC) community and EMBL-EBI to help researchers bridge the gap between theory and practice.
An international joint effort spanning the course of a year has produced a cutting-edge self-paced training resource in structural biology. The Foundations of protein structure module was developed by the Australian Structural Biology Computing (ASBC) community, the European Molecular Biology Laboratory European Bioinformatics Institute’s (EMBL-EBI) Protein Data Bank in Europe, and BioCommons, with the aim of providing accessible training for researchers who want to understand and use protein structures in their work.
‘Alignment, adoption and contribution to global best-practice efforts’ were aims of the Australian Structural Biology Deep-Learning Infrastructure Roadmap, developed in partnership between the ASBC and BioCommons in 2025. By co-designing this module with our partners at EMBL-EBI, we are excited to contribute to the resources they provide to an international audience of researchers.
What is the module and how does it benefit researchers?
Many researchers, undergraduates and clinicians want to use protein structures in their work, but don’t necessarily have the prerequisite knowledge to bridge the gap between theory and practice. This module onboards researchers to the domain, by providing an understanding of the fundamental concepts of protein structural biology, including protein composition, folding, architecture, dynamics, and interactions.
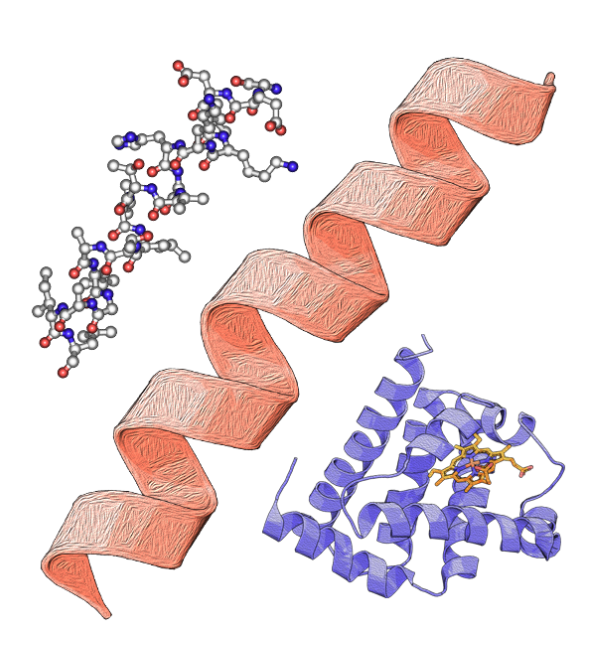
Protein structure elements (Image: EMBL-EBI Training)
For example learners gain insight into:
The sequence-structure-function relationship
Secondary, tertiary and quaternary structures, including alpha helixes and beta sheets, motifs, domains, and folds
The dynamic and flexible nature of proteins and how this impacts biological function.
Who developed ‘Foundations of structural biology’?
The module was co-designed over twelve months by collaborators based across Australia and the United Kingdom. As the team was working across continents and vast time zones, they relied on a mix of asynchronous drafting and regular online meetings for coordination, planning, and discussion of the content.
The contributors were:
From the ASBC and BioCommons: Dr Michael Healy (University of Queensland), Dr Kristina Gagalova (Curtin University), Dr Kate Michie (UNSW), Dr Thomas Litfin (UNSW and Australian BioCommons), and Dr Johan Gustafsson (Australian BioCommons)
From EMBL-EBI: Dr Jennifer Fleming, Dr Paulyna Magaña, Dr Flaminia Zane (reviewer), and Dr Ajay Mishra (reviewer).
Beyond the module itself, this project has strengthened the connection between EMBL-EBI, the ASBC, and BioCommons, and will lead to further collaboration on a set of structural bioinformatics modules that will complement and extend existing EMBL-EBI training resources.
Foundations of protein structure has been released as an online tutorial by EMBL-EBI Training as part of their mission to deliver world-class training in data-driven life sciences.