News
Subscribe to the Australian BioCommons monthly newsletter or read previous editions
Collaborating globally to develop a foundational structural biology training module
‘Foundations of protein structure’ is a new self-paced training module developed in collaboration with the Australian Structural Biology Computing (ASBC) community and EMBL-EBI to help researchers bridge the gap between theory and practice.
An international joint effort spanning the course of a year has produced a cutting-edge self-paced training resource in structural biology. The Foundations of protein structure module was developed by the Australian Structural Biology Computing (ASBC) community, the European Molecular Biology Laboratory European Bioinformatics Institute’s (EMBL-EBI) Protein Data Bank in Europe, and BioCommons, with the aim of providing accessible training for researchers who want to understand and use protein structures in their work.
‘Alignment, adoption and contribution to global best-practice efforts’ were aims of the Australian Structural Biology Deep-Learning Infrastructure Roadmap, developed in partnership between the ASBC and BioCommons in 2025. By co-designing this module with our partners at EMBL-EBI, we are excited to contribute to the resources they provide to an international audience of researchers.
What is the module and how does it benefit researchers?
Many researchers, undergraduates and clinicians want to use protein structures in their work, but don’t necessarily have the prerequisite knowledge to bridge the gap between theory and practice. This module onboards researchers to the domain, by providing an understanding of the fundamental concepts of protein structural biology, including protein composition, folding, architecture, dynamics, and interactions.
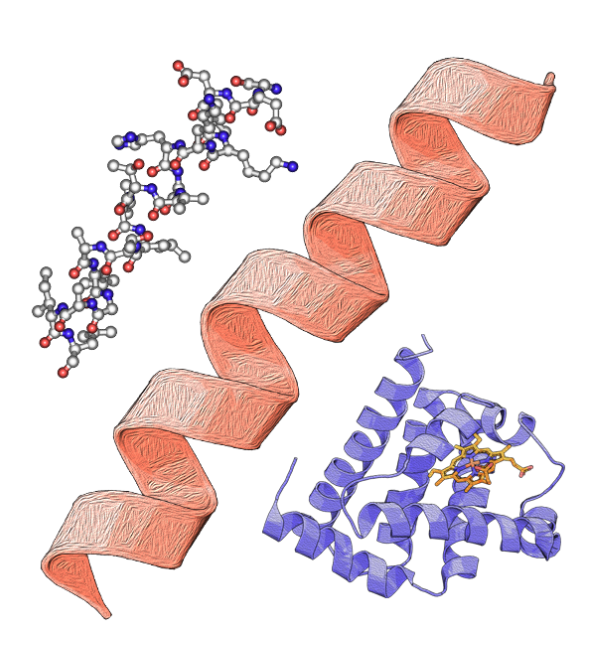
Protein structure elements (Image: EMBL-EBI Training)
For example learners gain insight into:
The sequence-structure-function relationship
Secondary, tertiary and quaternary structures, including alpha helixes and beta sheets, motifs, domains, and folds
The dynamic and flexible nature of proteins and how this impacts biological function.
Who developed ‘Foundations of structural biology’?
The module was co-designed over twelve months by collaborators based across Australia and the United Kingdom. As the team was working across continents and vast time zones, they relied on a mix of asynchronous drafting and regular online meetings for coordination, planning, and discussion of the content.
The contributors were:
From the ASBC and BioCommons: Dr Michael Healy (University of Queensland), Dr Kristina Gagalova (Curtin University), Dr Kate Michie (UNSW), Dr Thomas Litfin (UNSW and Australian BioCommons), and Dr Johan Gustafsson (Australian BioCommons)
From EMBL-EBI: Dr Jennifer Fleming, Dr Paulyna Magaña, Dr Flaminia Zane (reviewer), and Dr Ajay Mishra (reviewer).
Beyond the module itself, this project has strengthened the connection between EMBL-EBI, the ASBC, and BioCommons, and will lead to further collaboration on a set of structural bioinformatics modules that will complement and extend existing EMBL-EBI training resources.
Foundations of protein structure has been released as an online tutorial by EMBL-EBI Training as part of their mission to deliver world-class training in data-driven life sciences.
Help shape the future of AI in life sciences research and training
We are inviting community input to help shape the future of AI in life sciences. By participating in our survey and focus groups, you’ll help guide infrastructure priorities and shape our training program to benefit the Australian research community.
Artificial intelligence (AI) and machine learning (ML) are rapidly changing the way we work in life sciences. To ensure our community is well supported, Australian BioCommons is gathering input to map exactly how these technologies are being applied, particularly regarding molecular data analysis.
By sharing the current tools, processes, bottlenecks and skill gaps you experience, you will help prioritise national investments in digital infrastructure and directly shape our upcoming training programs.
How can you help shape the 2026 priorities?
We are looking for researchers and support staff at all levels of experience, from those who have never used AI to those who rely on it every day. Your perspective is valued regardless of your technical background.

There are two ways you can contribute:
Add your voice to the survey: Contribute to our national data collection to help identify trends and gaps across the Australian research ecosystem.
Join a focus group to contribute to our training programs: Share your specific challenges and ideas in a 60-minute interactive Zoom discussion. Register your interest by Friday 20 March 2026.
What happens next with your feedback?
We value your time and insights and we want to share what we learn along the way. In April, we will present a summary of our findings back with the community in a dedicated webinar. We will take a look at the initial training plan, giving you a sneak peek into the workshops and resources we’ll be launching later this year.
Introducing Spatial Sampler, the ‘cheat sheet’ to answering biological questions
A new tool is available to help researchers quickly answer important questions about their spatial omics data. This new resource, called Spatial Sampler, collates example R scripts for a variety of comparative analyses to fast track analysis.
A new tool is available to help researchers quickly answer important questions about their spatial omics data. This new resource, called Spatial Sampler, collates example R scripts for a variety of comparative analyses to fast track analysis.
QCIF Digital Research Senior Bioinformatician, Dr Sarah Williams, developed the resource for her own use, and upon realising its potential value to others she went on to share the collection of examples via the BioCommons’ Workflow Commons project.
What is Spatial Sampler?
Spatial Sampler is a collection of ‘How-To’ guides framed around testing specific biological questions.
Each How-To includes:
An example workflow using a real dataset, which explains why each step is necessary
What input data is needed
What the output looks like
A code snippet that can be copy-pasted
Who needs Spatial Sampler?
Spatial Sampler is a collection of complete, step-by-step workflows using real data that run comparative tests between different experimental conditions. The worked examples act as a ‘cheat sheet’ for spatial omics analysis. Most existing tutorials stop at the quality control and clustering stages, and a need for testing between groups is what inspired Sarah to develop Spatial Sampler:
When I started working with spatial data, I could find tutorials for how to load, QC and annotate my datasets. But I struggled to find complete workflows for testing experimental questions. I wanted a collection of examples using real data - so that’s what Spatial Sampler aims to provide. I had inspiration from amazing existing resources such as The R Graph Gallery. I’m now looking forward to others using Spatial Sampler and contributing more tools and resources that the community can use.”
Different elements of Spatial sampler will help different people:
Newcomers to spatial omics can apply worked examples to their own datasets
Busy bioinformaticians can use code snippets to run specific tests without rewriting code
Trainers can readily adapt open source instructions for their own training.
What is spatial omics?
Spatial omics combines the power of single-cell transcriptomics with spatial localisation, allowing researchers to measure gene expression and morphology while retaining the individual locations of transcripts within their native tissue environment. By inheriting analytical strengths from both single-cell technologies and microscopy, it enables the testing of complex new hypotheses about expression patterns and cellular interactions that are lost in data from a single modality.
This exciting new field is now moving from a niche to a fully-fledged production analysis technique, and given the rapid growth in utilisation, analysis methods are constantly being invented as new applications are discovered. Now that it is possible to generate high-quality data at scale, the downstream analysis options have expanded accordingly to help answer specific biological questions.
An example of this is in quantifying changes in the tumour microenvironment, such as changes in cell type composition between tumour subtypes, changes in immune cell migration between groups, or expression changes in different cells by experimental group or tissue region.
Spatial Sampler was initially developed by Sarah to analyse data from the Griffith Central Facility Genomics for A/Prof Nic West and Dr Amanda Cox (Griffith University) relating to their research projects in the mucosal immunology and cancer immunology spaces.
Sarah’s role at QCIF Digital Research is co-funded by Australian BioCommons.
Register now for the workshop that will provide a practical introduction to comparative analysis of spatial omics data using Spatial Sampler
Taking Nextflow to the next level: HPC Workshop applications now open
A new workshop will build practical skills to configure, optimise, and troubleshoot Nextflow pipelines for efficient and scalable execution on High Performance Computing (HPC) systems. It builds on the success of a recent national in-person training event attended by 90 life science researchers.
Life sciences research increasingly depends on analysing large and complex datasets. Tools like the workflow management system, Nextflow, can make this process reproducible, scalable, and efficient. But for many researchers, getting started with Nextflow can feel like a daunting leap.
Earlier this year the Nextflow for Life Sciences workshop introduced the fundamental principles of Nextflow pipeline development and guided newcomers to build reproducible and scalable scientific workflows with Nextflow, creating a multi-sample Nextflow workflow for RNAseq data preparation as an example. Led by trainers from the Australian BioCommons team at SIH, University of Sydney and supported by the National Bioinformatics Training Cooperative, 90 learners gathered at satellite sites in Sydney, Melbourne, Brisbane, Adelaide, Canberra and Perth, giving researchers the chance to connect locally with peers while benefitting from the national-level training.

Participants praised the balance of theory and practice, and nearly 90% of attendees rated the content as “very good” or “excellent”. A key highlight was the use of research-relevant datasets that empower scientists to apply their new skills directly to their work. As one participant reflected, “I got lots of knowledge on how to build my own Nextflow pipeline. The RNAseq example was fantastic - so many workshops use ‘Hello World’ examples that are impossible to scale up.”
We are excited to announce that applications are now open for our follow up workshop Nextflow on HPC to be held in November. This hands-on workshop will will provide participants with the practical skills to configure, optimise, and troubleshoot Nextflow pipelines for efficient and scalable execution on High-Performance Computing (HPC) systems.
Participants can expect to learn how to identify the differences between traditional HPC job submission and workflow execution via Nextflow, and how to best configure and execute scalable Nextflow workflows on HPC systems. Managing software environments using tools like singularity, and adapt these to fit within different HPC ecosystem constraints will be covered, along with tips on troubleshooting Nextflow workflows on HPC systems.
To make the most of this workshop you’ll need to have experience running simple Nextflow pipelines, and be looking to scale up your workflows to an HPC environment. You will be supported with access to national Tier 1 computing resources at Pawsey and NCI, so you must be associated with an Australian organisation.
These Nextflow workshops are part of Australian BioCommons’ mission to make advanced bioinformatics tools more accessible to researchers across the country. By combining national expertise with local support, this training is helping build capacity and strengthen the life sciences community.
Find out more about the workshop and submit your application: Nextflow on HPC.
Applications close 3 November 2025.
Thousands join international Galaxy training events
The Galaxy platform is celebrating its 20th anniversary this year and Galaxy Australia is one of the core BioCommons services. We are proud to provide and support a variety of opportunities for researchers to engage with the team, community and tools.
The Galaxy platform is celebrating its 20th anniversary this year. This collaborative data analysis platform is widely used by scientists around the world, and underpins many computational biology services. Galaxy Australia is one of the core services BioCommons delivers, so naturally we provide lots of opportunities for researchers to engage with the team, community and tools.
The Galaxy Australia team recently supported the Singapore Biology League, who chose to incorporate Galaxy into their online collaborative biology contest for the first time. This massive event welcomed over 2000 pre-university students who formed teams to run 2054 tools on Galaxy Australia over 4 hours. It was a great opportunity to broaden participants’ exposure to biology and bioinformatics beyond the school curriculum.
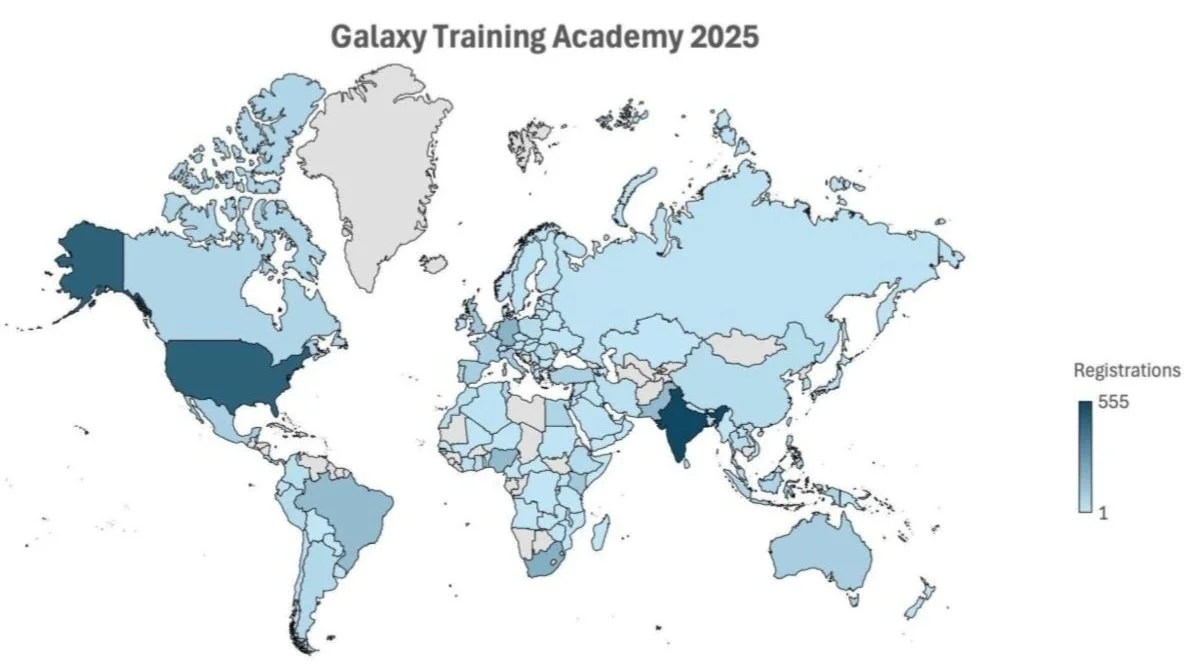
The week-long Galaxy Training Academy attracted more than 3500 people from across the globe this year. Seventy three Australian researchers were amongst the international cohort joining from their homes and offices to work through tutorials, with support as they needed it. Live help was provided in our time zones by Galaxy Australia’s Dr Anna Syme, Dr Igor Makunin and Dr Tristan Reynolds, who fielded questions on a wide range of topics from fungal genomics to bat ecology! Participants brought their own specialities as they learned how to use the fully subsidised Galaxy Australia platform for proteomics, genome assembly, transcriptomics, single cell RNAseq, microbiome analysis, machine learning and more.
In the lead up to the Galaxy Training Academy, BioCommons’ Dr Tiffanie Nelson and Galaxy Australia’s Dr Tristan Reynolds helped researchers understand what’s possible by presenting the webinar: No code, no problem: data analysis for biologists with Galaxy Australia. Examples included how Galaxy Australia is being used for biosecurity screening, foodborne pathogen detection and building reference genomes of the critically endangered swift parrot, as well as a tour of the practical features of Galaxy Australia that make sophisticated workflows like these accessible to all, regardless of their computational skills.
Get started by exploring the tutorials available: Galaxy Training Network
If you’re an existing Galaxy Australia user, improve your methods with our Top Tips videos
Stop the rot! Plant Bacteriologist’s genome assembly becomes Galaxy Australia’s 11 millionth job
An enthusiastic new user recently submitted the lucky 11 millionth data analysis job to the Galaxy Australia platform. Plant Bacteriologist Dr Toni Chapman has begun regularly using the fully-subsidised service for her genome assemblies of bacteria important to agricultural plant biosecurity and production.

Image courtesy of Dr Toni Chapman
An enthusiastic new user recently submitted the lucky 11 millionth data analysis job to the Galaxy Australia platform. Plant Bacteriologist Dr Toni Chapman has begun regularly using the service for her genome assemblies of bacteria important to agricultural plant biosecurity and production.
As a Senior Research Scientist in Agriculture and Biosecurity at the NSW Department of Primary Industries and Regional Development (DPIRD), Toni’s work spans both diagnostics and research. Using NovaSeq and HiFi sequencing technologies, she assembles bacterial genomes to help growers diagnose the cause of disease symptoms in their plants or to identify bacteria present in suspect samples collected by biosecurity officers.
In the past, Toni needed to rely heavily on bioinformaticians for assistance with genome assembly of the bacteria she works with. Now after attending a training workshop and signing up for access to the fully-subsidised Galaxy Australia service, she independently completes more of the analysis steps and is able to identify the bacterial pathogens herself.
“Over time I have been learning to code and to use various programs for genome assembly, but only returning to it on a casual basis makes it very hard to maintain the necessary skills in the bioinformatics space. Being able to design workflows in Galaxy Australia that I can come back to at any time makes assembling genomes easy, even if there has been weeks or months between visits.”
Toni contributes to the Plant Pathogen ‘Omics Initiative, which is generating molecular reference data for plant pathogens in Australia. Established by Bioplatforms Australia to support research in plant protection and enhance biosecurity surveillance efforts, the national plant pathogen community is collaborating to create high quality data that can be shared with all researchers via the Data Portal. Toni was one of a large group that came together with members of the Functional Fungi and Plant Pathogen ‘Omics National Initiatives for a hands-on bioinformatics workshop, learning how to use Galaxy and the programs needed for genome assembly using their own real-world scenarios.
As part of her contribution to the Initiative, Toni is conducting genome assembly on Pseudomonas species that cause disease in plants, to update the taxonomy of collection isolates and gain a more accurate view of which pathogens are in Australia. In another project, she is sequencing the bacterial pathogens that cause soft rot disease in plants. The incidence of soft rot is increasing, and so is the range of bacteria that can cause the disease. The newly assembled genomes of these bacteria are updating existing culture collection identities and helping to understand the diversity of bacteria that cause soft rot infections in Australia.
If you’d like to find out more about her work, see Dr Toni Chapman’s publications.
If you are interested in hearing about the different types of research that Galaxy Australia gets used for, watch this recorded webinar: No code, no problem - data analysis for biologists with Galaxy Australia.
Join a Metagenome Assembled Genomes hackathon
The “Optimising MAGs-building workflows hackathon” is taking place in October and we want to know if you’d like to join! An international group is participating in Europe, and BioCommons is planning to offer a complementary event in Australia. Please join us if you are interested in enhancing MAGs-building workflows, developing user-friendly training materials, advancing workflow evaluation methods, or building intelligent computational resource estimation tools.

The Optimising Metagenome Assembled Genomes building workflows hackathon is taking place in October and we want to know if you’d like to join!
Multiple ELIXIR nodes and the international Galaxy community are coming together in Europe to participate, and BioCommons is planning to offer a complementary event in Australia.
What is this?
Hackathons involve collaborative group work with people outside your normal network, solving problems around a shared topic of interest within a limited period of time. The aims of the event are:
Enhancing FAIR MAGs building Workflows
Developing user-friendly training materials
Advancing workflow evaluation methods (using CAMI infrastructure & real data)
Building intelligent computational resource estimation tools
The event takes place 6-9 Oct 2025. It will run in person in Freiburg, Germany and online. If there is enough interest, BioCommons will organise an in-person event in Australia to overlap with the European event.
What’s in it for me?
Collaborative group work: You'll work with people outside your usual network.
Expert connections: You'll connect with a national and international group of experts and enthusiasts.
Workflow enhancement: You'll contribute to enhancing MAG workflows.
Training material development: You'll participate in developing related training materials.
Skill development: While specific skills are not required, you can enhance your knowledge of microbiome data analysis or MAGs.
International participation: Opportunity to participate in an international hackathon with colleagues in Europe.
Who can join in?
It is open to anyone who wants to build MAGs or anyone with a general interest in MAGs, microbiome analysis and the associated training to run MAG workflows. To join in the hackathon, some knowledge of microbiome data analysis or MAGs is preferred. There is no cost to join.
How would this work?
Australian BioCommons regularly run satellite events that facilitate participation in global hackathons. If there is interest, we would ideally work together in person in Australia. Given European business hours coincide with Australian evenings, we would connect with the European hackathon team during some overlapping hours in the afternoon and work asynchronously for the other hours.
Are you interested in joining in?
If you think that you might be interested to join in this hackathon event, please get in touch with Tiff Nelson by 20th June 2025.
Nextflow workshop combines benefits of hands-on training and community building
BioCommons’ Nextflow for the life sciences workshop heralds a return of our dispersed model of hands-on training. By connecting supported in person satellite sites with online trainers this workshop enables access to Nextflow experts and fosters local connections that are essential for continued learning.

BioCommons’ Nextflow for the life sciences workshop heralds a return of our dispersed model of training that combines the benefits of in person and online events to enable access to experts and foster local connections that are essential for continued learning. First pioneered in 2019, this model has been successful in ensuring scalable and more equitable delivery of short-course bioinformatics training across Australia and has been adapted internationally.
Nextflow for life sciences workshop participants will join in person satellite sites at host universities and research institutes across Australia where they will connect with peers and be supported by experienced local facilitators as they put their new Nextflow skills into action. Each of these sites will connect online with Nextflow experts and lead trainers Fred Jaya and Dr Michael Geaghan at the University of Sydney’s, Sydney Informatics Hub who will introduce key concepts and demonstrate how to use fundamental Nextflow elements to develop, execute, and debug a scalable multi-step life science workflow.
Find out more and apply for the workshop. Applications close 27 June 2025.
This workshop is made possible by an exceptional network of facilitators and trainers from the national Bioinformatics Training Cooperative.
New seminar series ignites curiosity and builds practical AI skills in the life sciences
A series of webinars will feature Australian researchers from across academia and industry sharing their experiences of using AI in the life sciences. Hear how AI is being used to push boundaries, solve problems, and reimagine the way we do science. From multi-omics analysis to drug discovery, structural biology and the ethics of AI in science, these free events will explore diverse and practical applications across the life sciences, focusing on the stories, insights, and experiences behind the research.

AI is reshaping life sciences by enabling researchers to analyse complex datasets, automate workflows, and gain deeper insights into biological processes. Australian BioCommons is supporting the community to adopt these technologies through a series of training events that explore what’s possible and build skills in using AI effectively.
We’ve invited a diverse range of your peers from across academia and industry to share their experiences of using AI in the life sciences. Between June and September you’ll hear how AI is being used to push boundaries, solve problems, and reimagine the way we do science. From multi-omics analysis to drug discovery, structural biology and the ethics of AI in science, they will explore diverse applications across the life sciences, focusing on the stories, insights, and experiences behind the research.
In August, our online workshop Machine learning in the life sciences will provide a hands-on opportunity to compare and contrast commonly used algorithms for constructing predictive models, explore some of their trade-offs and identify types of scenarios in which they can be applied.
In case you missed it, Australian BioCommons’ AI Technical Lead, Dr Benjamin Goudey, recently broke down AI concepts, clarified key terminology, and showcased real-world examples in this recorded webinar: Deciphering AI for the Life Sciences.
AI is a fast evolving field so rest assured that further events are in the pipeline.
Building bridges for better data sharing: ENA experts empower Australian researchers in data submission
A visit from the European Nucleotide Archive (ENA) team enhanced Australian researchers’ skills in submitting and retrieving genomic, metagenomic, and environmental DNA (eDNA) data to/from international repositories. The two weeks together provided a unique opportunity to engage directly in our time zone through an intensive series of workshops and roundtable discussions.

Participants of the in-person roundtable came from around Australia to meet the ENA team
For two weeks in March and April 2025, Australia’s life sciences community had a unique opportunity to engage directly with the European Nucleotide Archive (ENA) team. In a first-of-its-kind initiative, Dr Joana Pauperio (Biodiversity Curator, European Nucleotide Archive, EMBL’s European Bioinformatics Institute) and Maira Ihsan (User Support Bioinformatician, European Nucleotide Archive, EMBL’s European Bioinformatics Institute) visited Australia to deliver an intensive series of seven workshops and four roundtable discussions, aiming to enhance Australian researchers’ skills in submitting and retrieving genomic, metagenomic, and environmental DNA (eDNA) data to/from international repositories.
Organised by Australian BioCommons, the visit built technical capacity and opened a direct dialogue between the ENA and the Australian research community about the future of data submission, retrieval, and brokering. High-quality data submission to international archives like the ENA ensures that Australian-generated genomic and environmental data can contribute to global research efforts. Yet, challenges in submission processes, metadata preparation, and understanding of repository workflows can act as barriers. Bringing ENA experts together in person allowed Australian researchers to receive tailored, hands-on guidance, overcoming time zone challenges and helping the ENA team witness firsthand the hurdles local researchers face.
Workshops: Hands-on learning and capacity building
Across six data submission workshops, participants learned various data submission pathways (e.g., via Webin-CLI, programmatic, and command line) to submit:
Raw reads, genome assemblies, and annotations
Metagenome-Assembled Genomes (MAGs)
Environmental DNA (eDNA) data
A data retrieval workshop provided an opportunity for participants to practice retrieving different data types from the ENA using various tools and protocols.
Feedback was welcome at all times by providing a living document for queries that were addressed during and after the workshop, and breakout rooms for 1:1 discussions were available.
Roundtables: Listening to the community
One in-person and three online roundtable discussions were also hosted to facilitate direct communication between ENA and Australian researchers.
In-person Roundtable
This meeting between invited members of Bioplatforms Australia, Bioplatforms Australia Data Portal, Australian Reference Genome Atlas (ARGA), the Australian Tree of Life project, and the ENA teams focused on information exchange and potential collaboration in the global biodata landscape. Key topics included data brokering to ENA, species taxonomy, and the possibility of establishing an Australian node within the International Nucleotide Sequence Database Collaboration (INSDC). The immediate next step identified was to further explore data brokering. The roundtable provided a valuable forum for discussing opportunities and challenges in collaborating with the ENA and enhancing Australia's contribution to international data repositories.
Genomics Roundtable
The meeting facilitated discussions on topics including Genome assembly and annotation efforts at scale in Australia, ENA's role as a global repository and challenges in annotation submissions to INSDC. It aimed to improve understanding of data publication options and ENA submission processes.
MAGs Roundtable
The meeting facilitated discussions on topics including the use of MAGs in Australia, the role of ENA+MGnify as a global repository, challenges in mass submission of MAGs, issues with submitting MAG data for organisms not represented in the NCBI Taxonomy, and suggestions for improvement.
eDNA Roundtable
The meeting facilitated discussions on topics including eDNA use across various sectors, Australian eDNA reference library initiatives like the National Biodiversity DNA Library (NBDL), making eDNA data FAIR (Findable, Accessible, Interoperable and Reusable) and the ENA as a global repository for eDNA data, data interoperability between resources, and data sharing with third-party platforms like GBIF.
Looking ahead
The momentum generated by the workshops and roundtables will continue through:
The creation of self-paced training materials: by converting the workshop content and hosting it on the EMBL-EBI training website to ensure researchers have access to training when they need it
Efforts to explore an Australian data brokering pathway as part of the Australian Tree of Life (AToL) project
Strengthened connections between Australian researchers and INSDC repositories
By bridging expertise across continents, the collaboration between ENA and the Australian life sciences community is helping ensure that Australian research continues to have a strong, visible impact on the global stage.