News
Subscribe to the Australian BioCommons monthly newsletter or read previous editions
World-leading Australian science: 17M protein structures added to the AlphaFold Database to accelerate the fight against antimicrobial resistance
Australian researcher, George Bouras, has recently contributed an extraordinary 17 million protein predictions to the AlphaFold Protein Structure Database. This work was possible thanks to the availability of the ColabFold tool on Setonix AMD, the result of collaboration between BioCommons and the Pawsey Supercomputing Research Centre.
Australian researcher, George Bouras, has recently contributed an extraordinary 17 million protein predictions to an international open access database. The availability of the large-scale dataset in the AlphaFold Protein Structure Database will have a transformative impact on the international fight to combat antimicrobial resistance.
As the lead of the AllTheBacteria protein structure prediction project, the Adelaide University bioinformatician and current PhD student completed his world-leading work using resources made available through a BioCommons partnership with Pawsey Supercomputing Research Centre. George’s work became possible only when the right human and compute resources came together. Working closely with BioCommons, Pawsey’s Dr Sarah Beecroft containerised the ColabFold tool for use on Setonix's AMD GPUs. Once ColabFold was ported and stable, George could utilise the massive scale of Pawsey’s Setonix to create the 17 million structural predictions for bacterial proteins.
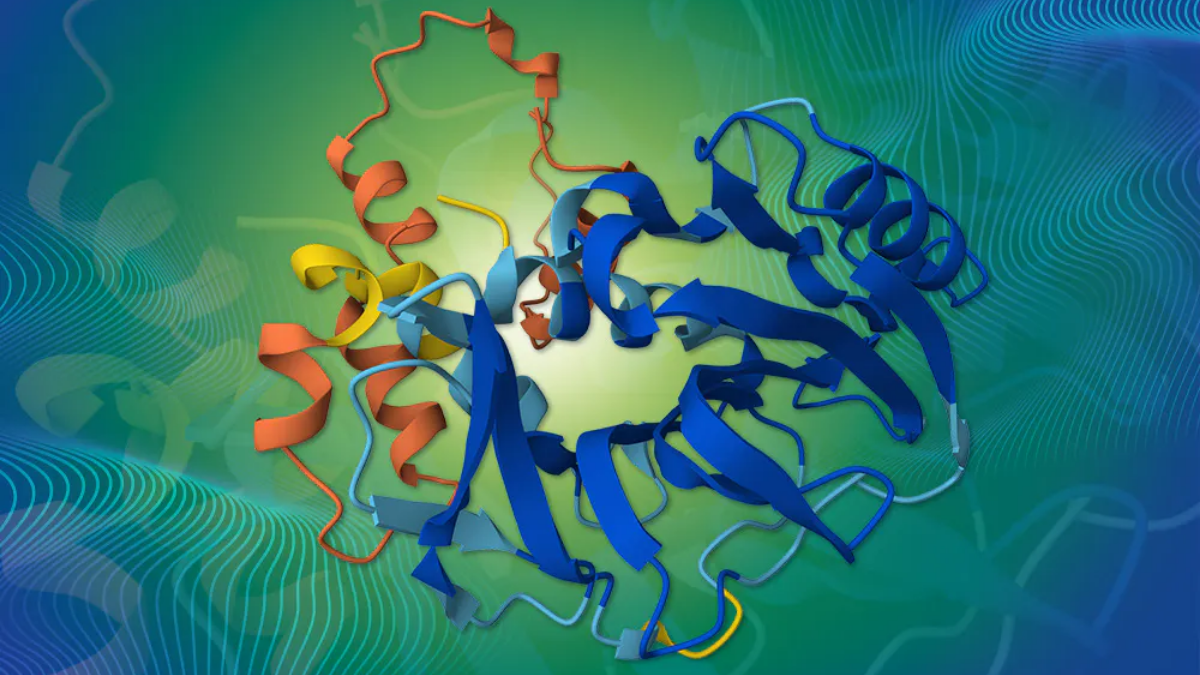
Source image: AlphaFold prediction of a banna virus spike protein VP4 (AF-0000000365762994-v1). Design credit: Karen Arnott/ EMBL-EBI.
George was honoured to contribute to the AlphaFold Database, one of several high-value datasets for microbial and viral proteins selected from specialist communities. This integration of essential, high-quality datasets from users reinforces the AlphaFold Database’s role as an inclusive, and community-driven resource. The database provides open access to over 200 million protein structure predictions, and the developers,Google DeepMind and EMBL’s European Bioinformatics Institute (EMBL-EBI), are wanting to expand their impact for specialist areas including pandemic preparedness, antimicrobial resistance, neglected tropical diseases and environmental sciences.
“I hope that access to these novel bacterial protein structures derived from high-quality genome assemblies will lead to better understanding of the function of all bacterial proteins.” – George Bouras, lead of the AllTheBacteria
The availability of the ColabFold container for use on Setonix’s AMD GPUs also allowed George to generate more than 3 million phage and viral structures, which are now used for protein structure-informed bacteriophage genome annotation hundreds of thousands of times each day by researchers around the world.
This example shows how close working relationships with both researchers and the Tier-1 HPC infrastructures enables BioCommons to precisely respond to community needs and accelerate Australian science at a scale. Making valuable tools accessible on national platforms is a focus of the BioCommons BioCLI project, and this work paves the way for the creation of a new national protein folding service further streamlining the use of Pawsey computing resources.
A publication about this work is currently under peer review, but in the meantime you can read the release from EBI.
GlyCombo: the first dedicated glycomics workflow on Galaxy
GlyCombo is now live on Galaxy Australia as the platform's first dedicated glycomics software tool. This high-throughput workflow, developed by Protea Glycosciences, offers researchers a streamlined, reproducible way to automate glycan identification from complex mass spectrometry data in just a few clicks.
In a win for the international glycomics community, the first dedicated glycomics and carbohydrate software tool is available on the global Galaxy platform thanks to a group of Australian researchers. GlyCombo, a high-throughput tool for glycan (sugar polymers present in protein samples) identification is now providing glycomics researchers with a streamlined, reproducible way to process their complex mass spectrometry (MS) data within Galaxy Australia. The workflow that performs a conversion of raw files, GlyCombo search, and visualisation of results glycan and polysaccharide compositions from mass spectrometry files has been shared through the publication on the GlyCombo Galaxy workflow on WorkflowHub.
The availability of this tool and workflow is the result of collaboration between the Galaxy Australia team and Protea Glycosciences, an innovative Australian glycosciences company based in Wollongong.

Dr Chris Ashwood and Dr Maia Kelly, Protea Glycosciences
By wrapping their open-source GlyCombo tool for Galaxy, Protea Glycosciences has made state-of-the-art analytical techniques accessible to researchers worldwide with just a few clicks.
How GlyCombo simplifies glycomics analysis
Rapid identification of glycans present in MS samples is a cornerstone of glycomics research and is integral to robust glycomics analysis pipelines, yet glycomics research is often limited by a lack of throughput and reproducible data analysis to enable subsequent structural elucidation. Protea Glycosciences was established in 2023 to address this gap, bringing a structure-oriented approach.
While traditional web-based tools utilise point-and-click interactions, GlyCombo enables researchers to rapidly process large-scale, complex MS datasets with greater efficiency and reproducibility. Through text-based commands, glycomics researchers can automate the assignment of monosaccharide combinations, handle multiple adduct searches, and anticipate off-by-one errors, while simultaneously maintaining detailed records of their analytical workflows.
The Galaxy GlyCombo workflow successfully monitored the glycomic consequences of biotransformation, detecting the drastic compositional shifts resulting from sialidase treatment directly within a fully reproducible, browser-based workflow.
Bringing the tool to Galaxy Australia
Protea Glycosciences have wrapped their open source tool for the platform, and the Galaxy Australia team have provided technical support to enable this easy access to the software. The integration of GlyCombo onto Galaxy Australia is a prime example of how national research infrastructure supports the Australian life sciences ecosystem, and how BioCommons and Galaxy Australia support industry-based Research and Development. Hundreds of researchers from Australian small-to-medium enterprises (SMEs) and startups use these subsidised services and the generous computational and working data storage quotas to accelerate their work.
“We built GlyCombo as an open-source tool to solve an analytical challenge, but software is only useful if people can run it. Galaxy makes complex workflows reproducible and accessible without local infrastructure or programming expertise. Partnering with Galaxy Australia was a direct path to putting rigorously tested glycomics workflows in front of researchers who need it and lowers the barrier to entry for the broader glycomics community.” - Dr Chris Ashwood, Director, Protea Glycosciences.
Learn more
Global collaboration advancing AI and biomedical data infrastructure
BioCommons brought together research data infrastructure experts from the USA, Finland, New Zealand and across Australia to strengthen the collaborative and technical capability required to build world-class human genomics and biomedical data infrastructure.
As part of a week-long international engagement program, BioCommons brought together research data infrastructure experts from the USA, Finland, New Zealand and across Australia. The Human Genome Informatics division at BioCommons hosted Prof Robert Grossman, University of Chicago, the founder and lead of the Gen3 platform, to strengthen the collaborative and technical capability required to build world-class human genomics and biomedical data infrastructure in Australia.
Participants engaged in a series of strategic discussions and technical demonstrations focused on solving the complex challenges of data commons development, federated data access, security and governance frameworks, and international interoperability initiatives.
Reflecting on the growing importance of research data infrastructure, Prof Matthew Watt, Associate Dean Research at the University of Melbourne’s Faculty of Medicine, Dentistry and Health Sciences, noted that ‘well-designed data ecosystems are no longer optional - they are foundational infrastructure for modern biomedical discovery.’

Prof Robert Grossman presenting during his seminar at the University of Melbourne
A particular highlight of the week was a seminar, ‘In Praise of Midscale Language Models and AI Commons and Their Applications to Biology, Medicine and Healthcare’, which sparked significant interest in how secure infrastructure can support the next generation of AI-driven biomedical research.
The discussions highlighted the value of strong international collaboration in advancing secure, scalable, and interoperable approaches to genomics and health data sharing, while also strengthening relationships across the global research infrastructure community. Participants noted the high quality of strategic conversations, which not only strengthened relationships but also reaffirmed Australia’s position as a leader in deploying these sophisticated systems.
How is Gen3 utilised in Australian human genomics research?
The Gen3 platform provides a robust framework to receive, manage, and describe massive datasets, allowing them to be shared securely with authorised users. It is the technology behind numerous US National Institutes of Health (NIH) projects that house data from hundreds of thousands of samples.
BioCommons has successfully led the implementation of Gen3 platforms for several landmark national projects, demonstrating our capability to adapt global best practices for the Australian research landscape. These include:
OMIX3: Led by the University of Melbourne, OMIX3 utilises mass spectrometry to enable the parallel collection of proteomics, metabolomics and lipidomics data, and is the first successful implementation of a Gen3 platform outside of the USA.
Australian Cardiovascular disease Data Commons (ACDC): Led by the Baker Heart and Diabetes Institute, ACDC provides a secure, Gen3-powered infrastructure to pool data from 400,000 individuals across 18 clinical cohorts.
Biological Psychiatry Data Commons (BPsych-DC): Led by the Consortium for Preclinical Psychiatric Research, providing a national digital infrastructure to harmonise multi-omics data across cellular, animal and human psychiatric models, bridging the gap between discovery and clinical impact
Prof Bernard Pope, GUARDIANS Program Lead and A/Director (Human Genome Informatics) at BioCommons, reflected on the highlights of the week:
‘Data commons are the backbone of collaborative genomic research. The ability to securely connect, govern, and analyse large-scale datasets is increasingly critical for translating research discoveries into meaningful health and clinical impact.’
‘The success of projects like OMIX3 and ACDC is built on years of shared expertise between our team and the architects of Gen3. By hosting international experts through the GUARDIANS program, we are ensuring that Australian researchers have access to the same secure, scalable technologies that power the world’s largest genomic projects.’
Take a closer look at the GUARDIANS Program: https://www.biocommons.org.au/guardians
Research communities can build their own digital labs with Australian innovation: Galaxy Labs Engine
The Galaxy Labs Engine is featured in a new paper detailing how researchers can build their own tailored digital labs. These bespoke interfaces provide curated tools and synchronised workflows that simplify complex, domain-specific bioinformatics for our community.
The Galaxy Labs Engine has been described in a new paper, including how it supports the easy creation of tailored research environments. Several domain-specific portals have now been generated on Galaxy Australia that guide researchers through curated and globally synchronised bioinformatics analysis resources
The Galaxy Labs Engine (GLE) allows research communities to build and synchronise their own Galaxy Labs, which guide users through curated tools, workflows, and training resources. These bespoke interfaces are especially helpful for researchers who are new to the analytical methods or technologies specific to the domain.

Galaxy Labs are an extension of the established feature of ‘Galaxy Flavours’, subdomains which offer curated content for specific research domains. However, these subdomains have been limited by having static deployments, being difficult to replicate across servers, and often provide inconsistent user interfaces. By separating the content from technical deployment, the engine allows research communities to build custom Labs that stay synchronised with global resources through GitHub.
Development of the GLE service was led by the Galaxy Australia team, originating from a project at the ‘Aussie Outpost’ of the ELIXIR BioHackathon Europe, hosted by Australian BioCommons in 2022.
The GLE has been used on the Galaxy Australia server to build the Microbiology and Single cell Labs, with the eDNA Lab currently being built, joining the Genome and Proteomics Labs as part of the expanding list of pre-configured Labs available. The engine is already being employed abroad by Galaxy France for their Ecology Lab, and to encourage global collaboration all Lab content is hosted in the Galaxy Project’s Codex GitHub repository.
Reflecting on how the team is always developing new ways to empower researchers, Galaxy Australia Product Owner Dr Gareth Price noted:
‘Our goal was to make constructing a Galaxy Lab an easy and accessible process for the whole community. Our team is already looking ahead as we finalise the deployment of an AI-assisted Lab builder, again reducing the technical barriers for researchers to start on their own Lab journey.’
You can read the paper in Gigascience
Explore the Galaxy Labs on the BioCommons website
Read Dr Gareth Price’s blog post on Galaxy News
Collaborating globally to develop a foundational structural biology training module
‘Foundations of protein structure’ is a new self-paced training module developed in collaboration with the Australian Structural Biology Computing (ASBC) community and EMBL-EBI to help researchers bridge the gap between theory and practice.
An international joint effort spanning the course of a year has produced a cutting-edge self-paced training resource in structural biology. The Foundations of protein structure module was developed by the Australian Structural Biology Computing (ASBC) community, the European Molecular Biology Laboratory European Bioinformatics Institute’s (EMBL-EBI) Protein Data Bank in Europe, and BioCommons, with the aim of providing accessible training for researchers who want to understand and use protein structures in their work.
‘Alignment, adoption and contribution to global best-practice efforts’ were aims of the Australian Structural Biology Deep-Learning Infrastructure Roadmap, developed in partnership between the ASBC and BioCommons in 2025. By co-designing this module with our partners at EMBL-EBI, we are excited to contribute to the resources they provide to an international audience of researchers.
What is the module and how does it benefit researchers?
Many researchers, undergraduates and clinicians want to use protein structures in their work, but don’t necessarily have the prerequisite knowledge to bridge the gap between theory and practice. This module onboards researchers to the domain, by providing an understanding of the fundamental concepts of protein structural biology, including protein composition, folding, architecture, dynamics, and interactions.
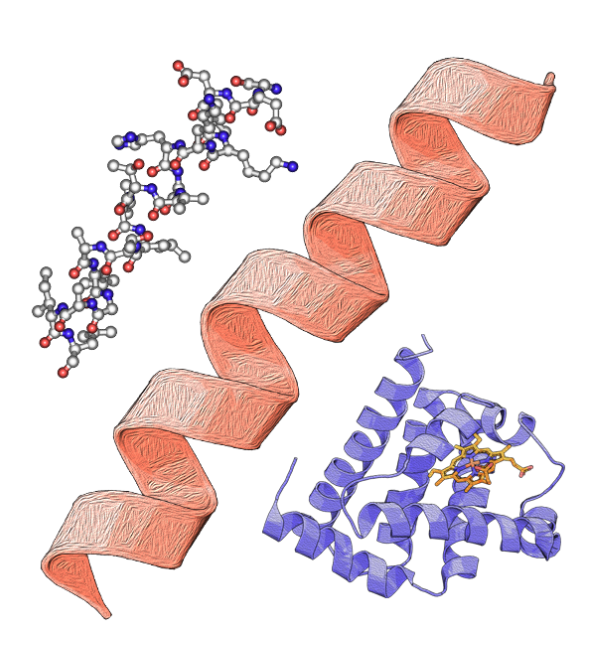
Protein structure elements (Image: EMBL-EBI Training)
For example learners gain insight into:
The sequence-structure-function relationship
Secondary, tertiary and quaternary structures, including alpha helixes and beta sheets, motifs, domains, and folds
The dynamic and flexible nature of proteins and how this impacts biological function.
Who developed ‘Foundations of structural biology’?
The module was co-designed over twelve months by collaborators based across Australia and the United Kingdom. As the team was working across continents and vast time zones, they relied on a mix of asynchronous drafting and regular online meetings for coordination, planning, and discussion of the content.
The contributors were:
From the ASBC and BioCommons: Dr Michael Healy (University of Queensland), Dr Kristina Gagalova (Curtin University), Dr Kate Michie (UNSW), Dr Thomas Litfin (UNSW and Australian BioCommons), and Dr Johan Gustafsson (Australian BioCommons)
From EMBL-EBI: Dr Jennifer Fleming, Dr Paulyna Magaña, Dr Flaminia Zane (reviewer), and Dr Ajay Mishra (reviewer).
Beyond the module itself, this project has strengthened the connection between EMBL-EBI, the ASBC, and BioCommons, and will lead to further collaboration on a set of structural bioinformatics modules that will complement and extend existing EMBL-EBI training resources.
Foundations of protein structure has been released as an online tutorial by EMBL-EBI Training as part of their mission to deliver world-class training in data-driven life sciences.
Meet the Team: Mok, UX Designer
Our team members bring deep expertise and broad experience. Hear how a UX Designer contributes to the BioCommons mission. Mok is our friendly translator who sits between complex systems and real humans, reshaping complicated processes into smooth, logical journeys.
Describe your role at BioCommons
I’m a user experience (UX) Designer at BioCommons, which means that I help improve infrastructure and scientific research by being the friendly translator between complex systems and real humans. This type of role is new in the life sciences field, making it a lot of fun, as I sit at the intersection of science, data, and human-centred design, helping researchers, bioinformaticians, and software engineers make sense of the inherently complex biological tools and platforms they use everyday. The goal is to make it look easy - even when it’s not!
It’s challenging work, because the problems are big and complex. You’re designing for expert users, emerging technologies, and systems that genuinely matter.

There’s a lot to learn, a lot to ask, and plenty of moments where curiosity and collaboration are essential. This makes the role deeply rewarding, as your work doesn’t just improve usability; it helps accelerate research, supports discovery, and amplifies the impact of national life-science infrastructure.
How can UX Designers improve infrastructure and/or scientific research?
Think of scientific infrastructure as a powerful machine: data platforms, tools, pipelines, and services that can do amazing things. A UX Designer ensures that people can actually use that power without needing a PhD in ‘figuring stuff out’.
By taking complicated processes and reshaping them into smooth, logical journeys, we turn confusion into clarity. This saves researchers time and frustration - when tools are intuitive, scientists spend less time wrestling with interfaces and more time doing what they love: discovering, analysing, and innovating.
Good UX also makes infrastructure more accessible. It opens the door for students and early-career researchers to use advanced systems confidently, rather than those tools being limited to the experts that already know the ropes. By asking the right questions early and understanding user needs upfront, we help teams build the right thing the first time. This reduces rework and ensures that research workflows flow smoothly, helping insights travel from idea to impact more quickly.
What is the real-world impact of human-centred design at BioCommons?
At BioCommons, my impact is all about making powerful research infrastructure feel simple, friendly, and usable. I focus on turning complex scientific tools into clear experiences, helping researchers spend less time navigating systems and more time doing great science.
By listening to users and smoothing out workflows, I help ensure that BioCommons tools are not just functional, but adopted and used to their full potential. In short: I make hard things easier, science faster, and national infrastructure more human.
What makes solving scientific problems so rewarding?
This is not your average UX gig, and that’s exactly the point. I get to work closely with scientists, engineers, product leads, and stakeholders who are passionate about what they do and who will happily stretch my thinking.
It is incredibly rewarding to work in a space where UX isn’t just ‘nice to have’, but genuinely transformative. There is a unique joy in those moments where a complex process suddenly becomes clear and usable.
In short: it’s a role for UX designers who like their work meaningful, their challenges meaty, and their wins shared with science itself!
Strengthening Australia’s Nextflow community through local and global collaboration
The Sydney satellite of the international nf-core Hackathon brought together members of the Nextflow and nf-core community to work collaboratively on a diverse range of projects.
The Australian satellite site of the 2026 nf-core Hackathon has just taken place at the BioCommons node at Sydney Informatics Hub, the University of Sydney. The hands-on event brought together members of Australia’s Nextflow and nf-core community to contribute to nf-core projects, while strengthening connections locally and across the global community.
Twelve participants from University of NSW, University of Sydney, and University of Melbourne came together to collaborate in person on cutting-edge nf-core projects, with support from two Nextflow Ambassadors on BioCommons’ team, Dr Georgie Samaha and Dr Ziad Al Bkhetan.
As one of 29 global hackathon sites, the Australian team contributed to the international nf-core effort through asynchronous collaboration. Given our geography, the team was among the first to kick off the work, closing each day by connecting with the APAC teams working from sites in Aotearoa New Zealand and South Korea.

Attendees at the satellite site at the Sydney Informatics Hub, University of Sydney
The group made meaningful contributions to several nf-core projects, working to: close open issues and make a release for the nf-core ProteinFold pipeline; develop a new ConfigBuilder tool in the nf-core tools suite that helps users build Nextflow configuration files; and edit Nextflow for HPC training materials to support implementation by others with new documentation for trainers.
It was wonderful to see the progress made by the productive participants over three days together, and the outcomes reflect the depth of expertise and collaborative spirit of the Australian community. We are grateful to all participants for the energy and enthusiasm they brought. Thanks also to the Seqera team and the nf-core community for their support for the Australian satellite site of the hackathon, and especially for sponsoring our delicious lunch together on the final day!
Want to learn how to run and customise nf-core workflows? The Unlocking nf-core: customising workflows for your research workshop is taking applications now, and registrations are also open for our upcoming webinar Using Containers in Nextflow.
AI for Science Hackathon connects industry with research to accelerate Australian science
Australian BioCommons partnered with NVIDIA, OpenACC, Monash University, NCI, Pawsey and SHARON AI to bridge the gap between industry hardware experts and life science researchers.
The AI for Science Australian Hackathon recently wrapped up in Melbourne, bringing together researchers and technical experts to port, accelerate and optimise research applications. The week-long event paired a select group of research projects with computational mentors and powerful compute tailored to their needs. Organised in collaboration with NVIDIA and OpenACC and hosted at Monash University, BioCommons also joined Pawsey Supercomputing Research Centre, National Computational Infrastructure and SHARON AI to boost projects across structural biology, advanced engineering, quantum chemistry and climate modelling.
What life science challenges were tackled?
Several teams leveraged the opportunity to translate software and hardware optimisations to existing medical and human health challenges. A key factor for teams applying to the event was to bring a mature project that could utilise the available mentorship and compute resources effectively.

Attendees, organisers and mentors of the hackathon
A group from the Australian Structural Biology Computing (ASBC) community brought interdisciplinary expertise from UNSW’s Structural Biology Facility, WEHI, and the Monash AI Protein Design Program to optimise protein structure prediction and design workflows. The project incorporated GPU-enabled MMSeqs2 for accelerated sequence search and improved throughput and memory use of the Boltz-2 implementation for structure prediction. This work has been contributed to community-maintained Nextflow nf-core pipelines to promote efficient workflows for researchers worldwide.
A joint Australian Centre for Artificial Intelligence in Medical Innovation (La Trobe University) and Florey Institute of Neuroscience and Mental Health team tackled a highly complex 20,000-line codebase dedicated to childhood dementia research. Their project focused on predicting whether mRNA sequence data could accurately target the specific NPC1 mutation responsible for the disease. BioCommons’ AI Technical Lead, Dr Benjamin Goudey supported this work as a dedicated mentor. By bridging the gap between the hardware experts and the life science researchers, Ben helped the team navigate their massive codebase to ensure their mRNA dementia research workflows could run efficiently on the accelerated GPUs.
What technical outcomes were achieved?
By exploring batched inference strategies, some workloads in the structural biology project saw a four-fold speed increase, alleviating major predictive bottlenecks in high value protein design workflows. The team also doubled their maximum prediction size by chunking operations at key memory bottlenecks and working around overflow bugs in high-level libraries like PyTorch and trifast. With access to impressive hardware in the form of eight NVIDIA B200 GPUs, participating teams achieved substantial performance gains as well as insights into maximising the benefit of GPU acceleration within their research.
The event was a major upskilling opportunity, with researchers experimenting with agentic coding, getting introduced to GPU-accelerated data processing libraries (NVIDIA RAPIDS), and working under the guidance of expert mentors to iterate their optimisations.
Reflecting on the event, Dr Thomas Litfin, a UNSW researcher supported by Australian BioCommons and member of the ASBC community, highlighted the immense value of this hands-on support, as well as the lasting impact of the connections forged during the week:
‘The groups got an incredible amount of value from the expert mentors, who were instrumental in suggesting strategies and troubleshooting bottlenecks on the fly. The event was also a great community building exercise for our project by bringing together people from Monash, WEHI, and UNSW, and creating opportunities for ongoing collaborations.’
As AI methodologies become increasingly embedded in the life sciences, BioCommons will continue working alongside our partners to ensure researchers have both the cutting-edge digital infrastructure and the specialised skills needed to use it.
Read more about the event in the blog post by host Monash University.
Hear what the National AI Survey told BioCommons about researchers’ AI needs in the Future of AI in Life Sciences webinar.


Contributing to open and accessible training with 500+ bioinformatics resources
The Galaxy Training Network offers tutorials covering everything from genomics to machine learning. These self-paced resources combine videos and worked examples, allowing researchers to master complex bioinformatics tools.
Did you know that an international community has been coordinating the creation of freely accessible educational data analysis training resources for over a decade? This sustained stewardship from the Galaxy community has resulted in a collection of over 500 tutorials covering 35 topics that have been written, reviewed and maintained by people committed to open and accessible training.
What do these training resources cover?
Galaxy Training is a collection of tutorials developed and maintained by the worldwide Galaxy community. There have been 511 contributors, including the Hall of Fame: Australian BioCommons team who have contributed to 37 tutorials in support of life sciences computation. The library of tutorials available in Galaxy Training cover a wide range of scientific fields including genomics, climate science, ecology, statistics, machine learning and more. The resources combine videos, slides and worked examples that are accessible to everyone to use in their own time. The Galaxy community also hosts a massive online training event online each year to provide a further layer of support to learners.
Different categories of training resources available
The group of BioCommons contributors work at Melbourne Bioinformatics, the University of Queensland, and QCIF Digital Research, supporting researchers through training and improvements to the Galaxy data analysis platform. The Galaxy Australia service is made available for Australian life science researchers to more easily perform their data analysis. The web-accessible platform offers fully-subsidised accessible, reproducible, and transparent computational biological research. The Galaxy Australia service contains over 2,000 bioinformatics tools (for genome assembly, annotation, epigenetics, metabolomics, metagenomics, proteomics, statistics, transcriptomics, variant analysis and visualisation) and over 220 reference datasets (e.g. publicly available genome builds).
There are now over 650,000 registered Galaxy users internationally, and the Galaxy Community is always encouraging new users to get more involved. There are lots of different ways to contribute to the Galaxy Training Network (GTN), from reporting suggesting tune-up opportunities as you step through the tutorials, all the way to creating new content you think would be useful to others. Contributions can be driven by an individual sharing a specific thing they developed in the hope that it can help someone else with a similar niche interest, or involve a large effort to coordinate big changes that will benefit a very large group of people. The integration of the Galaxy Training Network with WorkflowHub was made possible thanks to a collaborative effort between Australian BioCommons and the Galaxy Training Network and WorkflowHub teams. All Galaxy Training workflows are now registered with WorkflowHub, with workflows contained in every new tutorial automatically pushed to WorkflowHub.
Where can I access Galaxy Training resources?
Investigate the Galaxy Training workflows: Galaxy Training on WorkflowHub.
View a webinar introduction to using Galaxy Australia for different biological applications: No code, no problem: data analysis for biologists using Galaxy Australia - Dr Tiff Nelson and Dr Tristan Reynolds.
Register for the free and online Galaxy Training Academy 2026.
Galaxy Australia’s 14 millionth job was a win for sustainable crop production
Galaxy Australia solves the technical bottleneck for molecular biologists who need to perform high-level bioinformatics without dedicated coding expertise. Molecular Biologist, Dr Donald Gardiner, from University of Queensland, uses the platform to understand how pathogens cause disease in plants.
The 14 millionth data analysis job was recently submitted to the Galaxy Australia platform, marking another major milestone for this national service. University of Queensland Senior Research Fellow, Dr Donald Gardiner, uses the platform to understand how pathogens cause disease in plants. His work highlights how essential access to the right research infrastructure is in sustaining Australia’s agricultural and biodiverse future.
How does Galaxy Australia support sustainable agriculture?
As part of the Queensland Alliance for Agriculture and Food Innovation, Donald works in a diverse group that includes molecular biologists, plant pathologists and biotechnologists to solve plant disease problems. Their work has been central to the ARC Hub for Sustainable Crop Protection, looking at innovative ways to protect Australian agriculture.

Dr Donald Gardiner
Donald’s work using Galaxy Australia spans several research projects, focusing on pathogens threatening the nursery and garden, forestry, agriculture and horticulture industries, as well as natural ecosystems. He is investigating the impact of Myrtle rust on the Mytaceae family of plants, including eucalypts and tea tree. The threat that pathogen Fusarium oxysporum poses to Australia’s banana industry, and risks to ginger and cereal crops are all better understood by Donald’s use of Galaxy Australia’s tools for genome assembly, annotation, RNA-seq and phylogenomics analysis.
How do molecular biologists use Galaxy Australia for bioinformatics?
For researchers like Donald whose lab work is complemented by key steps involving bioinformatics, the platform serves as a ‘truly enabling’ resource.
‘Galaxy allows me to skip much of the backend set up work for getting pieces of software to run. As someone who is not solely undertaking bioinformatic work, the need to have relatively simple ways to run programs is really important as I can’t dedicate massive amounts of time to bioinformatics.’
The service provides a comprehensive suite of software tools that are ready to use, allowing life science researchers to focus on the biological impact of their work rather than how to perform the analysis themselves, or relying on external bioinformatics expertise.
Find out more about Dr Donald Gardiner’s research
Learn about the different types of research that Galaxy Australia gets used for: No code, no problem - data analysis for biologists with Galaxy Australia (webinar)